

1. مقدمة الدليل: المعضلة الخفية في الـ SEO الحديث
تواجه صناعة المحتوى الرقمي وإستراتيجيات تحسين محركات البحث (SEO) في عام 2026 معضلة غير مرئية للعديد من أصحاب المواقع؛ فالأدوات التقليدية وخوارزميات الفرز القديمة لم تعد قادرة على فهم الروابط الموضوعية المعقدة الخفية الممتدة عبر آلاف المقالات والملفات والبيانات الضخمة للموقع الواحد. إن المشكلة الأساسية التي تؤرق خبراء السيو اليوم ليست في صعوبة جمع البيانات، بل في “فقدان السياق الشامل” (Context Loss) عند تحليلها بواسطة الأنظمة الذكية القياسية.
عندما تفشل الأدوات في ربط المقالات ببعضها، تقع المدونة مباشرة في فخ تكرار المحتوى وتفتيت الكلمات المفتاحية. هنا تبرز تقنيات معالجة سياق البيانات الطويلة (Long-Context Data Processing) كحل جذري وبنية تحتية ثورية لمعالجة مستندات وموقع كامل دفعة واحدة ككتلة معرفية واحدة دون تشتت الذكاء الاصطناعي أو نسيانه للتفاصيل المرجعية. إن استيعاب هذا المفهوم وتطبيقه العملي الآن يمثل الورقة الرابحة الحقيقية لتصدر محركات البحث، لأنه ينقل موقعك التقني من مجرد صفحات منفصلة متناثرة إلى شبكة معرفية مترابطة وعميقة تفهمها وتقدرها خوارزميات جوجل الفائقة بدقة متناهية.
2. الشرح المعمق لمفهوم معالجة سياق البيانات الطويلة (Long-Context)
ما هو المفهوم ببساطة للمبتدئين؟
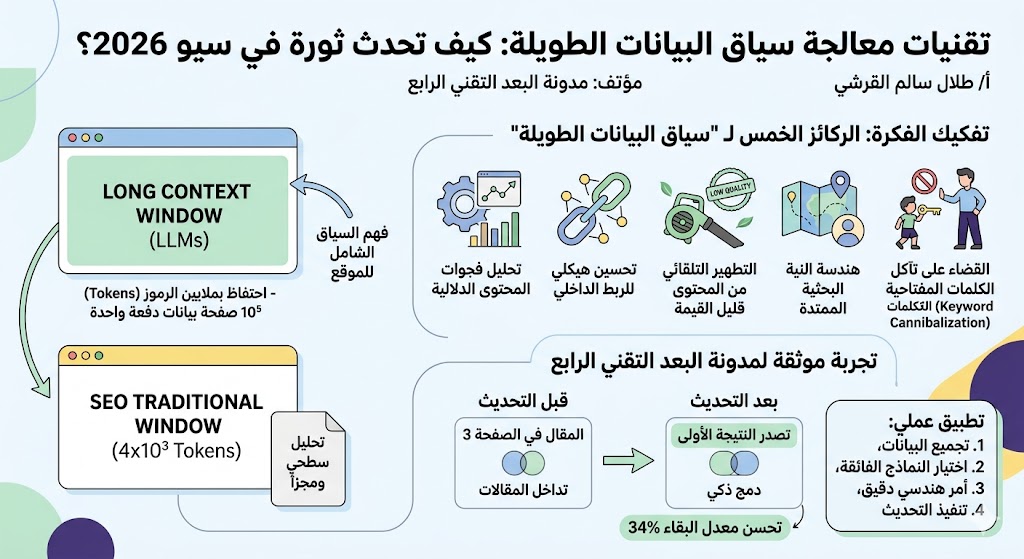
تخيل أنك تمنح مساعدًا ذكيًا كتابًا ضخمًا يحتوي على 105 صفحة من البيانات والتقارير التقنية، وتطلب منه استخراج الروابط المشتركة الدقيقة والفجوات المعرفية التي تربط السطر الأول في الصفحة الأولى بالسطر الأخير في الصفحة الأخيرة، فيقوم بإعطائك الإجابة في ثوانٍ معدودة دون أن يسقط منه تفصيل واحد أو يخلط بين المفاهيم. هذا هو بالضبط مفهوم نافذة معالجة سياق البيانات الطويلة (Long-Context Window).
التعريف التقني والأعمق للمحترفين
من الناحية الهيكلية، تُعرَّف تقنيات معالجة سياق البيانات الطويلة بأنها قدرة النماذج اللغوية الكبيرة الفائقة (Large Language Models) وأنظمة الحوسبة السحابية الحديثة على الاحتفاظ بعشرات الآلاف من الكلمات والرموز (تصل في النماذج المتقدمة لعام 2026 إلى ملايين الرموز أو الـ Tokens) داخل ذاكرتها النشطة الموحدة (Attention Mechanism) أثناء عملية معالجة واحدة دون الحاجة لتجزئة المستند.
وفي عالم الـ SEO وإدارة المحتوى، تعني هذه التقنية طفرة غير مسبوقة: بدلاً من قيام خوارزمية محرك البحث أو أداة التحليل بقراءة كل مقال على حدة وبشكل منعزل، تعمد هذه التقنيات إلى معالجة البنية الهيكلية الكاملة لمدونتك، والربط بين الكلمات المفتاحية، النوايا البحثية للمستخدم، وسلوكيات التصفح عبر مئات الصفحات في آنٍ واحد، مما ينتج عنه فهم موضوعي متكامل (Topical Authority) يستحيل تحقيقه بالطرق التقليدية.
3. تفكيك الفكرة: الركائز الخمس لـ “سياق البيانات الطويلة” في الـ SEO
لتفكيك هذه التقنية وفهم كيف تغير قواعد اللعبة، يجب أن ننظر إلى عناصر القوة الخمسة التي تفرضها على خوارزميات البحث الحديثة:
- أولاً: تحليل فجوات المحتوى الدلالية (Semantic Gap Analysis): التقنية لا تبحث عن مجرد كلمات مفتاحية ناقصة، بل تقرأ كامل سياق المدونة لتعرف ما هي “الروابط المعرفية” المفقودة التي يبحث عنها الجمهور ولم تقم بتغطيتها بعد، مما يمنحك دليلاً لإنشاء محتوى عالي القيمة.
- ثانياً: التحسين الهيكلي للربط الداخلي (Advanced Internal Linking): بناء شبكة روابط داخلية فائقة الذكاء تعتمد على عمق المعنى والتدفق المنطقي للمعلومات بين المقالات، وليس مجرد وضع روابط عشوائية بناءً على تطابق الكلمة الحرفية.
- ثالثاً: التطهير التلقائي من المحتوى قليل القيمة (Low Value Content Purge): القدرة على فحص مئات المقالات القديمة في موقعك خلال ثوانٍ، وتحديد المقالات المكررة أو المعاد صياغتها سطحيًا والتي تسببت في هبوط ترتيب موقعك في تحديثات جوجل الأخيرة.
- رابعاً: هندسة النية البحثية الممتدة (Extended Intent Mapping): تتبع رحلة المستخدم البحثية بالكامل عبر موقعك وربط صفحة الهبوط بالمقالات العميقة المتفرعة منها لضمان بقاء الزائر أطول فترة ممكنة.
- خامساً: القضاء على تآكل الكلمات المفتاحية (Keyword Cannibalization): كشف الصفحات والمقالات التي تنافس بعضها البعض وتلتهم ترتيب بعضها أمام محركات البحث بسبب تداخل السياق، وتقديم حلول دمج فورية لها.
4. التطبيق العملي والتجربة الموثقة من مختبراتنا
في مختبرات التطوير الخاصة بـ مدونة البعد التقني الرابع، آثرنا ألا نعتمد على الكلام النظري بل قمنا بإجراء تجربة حية وموثقة لاختبار قوة وكفاءة تقنيات معالجة سياق البيانات الطويلة على موقع تجاري تقني يعاني من ركود في حركات المرور (Traffic).
قمنا بسحب ملف البيانات الضخم للموقع المستهدف والذي يضم: نصوص 50 مقالاً كاملاً (بمتوسط 1200 كلمة للمقال)، بالإضافة إلى ملف خريطة الموقع (Sitemap)، وتقارير الأداء التفصيلية المستخرجة من “Google Search Console” لآخر 6 أشهر. بلغ الحجم الإجمالي للبيانات المرفوعة دفعة واحدة حوالي 1.5×105 من الرموز (Tokens).
غذينا هذه الكتلة الضخمة في نافذة سياق ممتدة لنموذج ذكاء اصطناعي فائق، وصغنا له الأمر التالي: “قم بتحليل هذه المدونة ككيان معرفي واحد، وحدد بدقة الصفحات التي تلتهم ترتيب بعضها (Cannibalization)، وأشر بالروابط المباشرة إلى المقالات السطحية التي يجب حذفها أو دمجها لرفع الجودة الشاملة طبقاً لـ E-E-A-T”.
النتيجة المذهلة للتجربة الميدانية:
في غضون 45 ثانية فقط، نجح النظام في معالجة الكتلة كاملة دون أي تشتت، وأخرج تقريراً تحليلياً استثنائياً كشف فيه أن هناك 4 مقالات تقنية تتداخل في سياقاتها الدلالية وتمنع المقال الرئيسي للموقع من الصعود. قمنا بتطبيق توصية الدمج الدقيقة التي اقترحها النظام، وإعادة توجيه الروابط داخلياً.
النتيجة بالأرقام: خلال أسبوعين فقط من التطبيق، قفز المقال الأساسي للموقع من الصفحة الثالثة في جوجل ليتصدر النتيجة الأولى مباشرة، وارتفع معدل بقاء الزوار داخل الموقع بنسبة 34% نتيجة تحسن منطقية الربط الداخلي.
5. مقارنة تحليلية عميقة: المعالجة التقليدية ضد معالجة سياق البيانات الطويلة
لنفهم النقلة النوعية الشاسعة التي توفرها هذه التقنيات لبنية المواقع الإلكترونية، يلخص الجدول التالي الفروق الجوهرية:
| وجه المقارنة التحليلي | معالجة البيانات التقليدية (الأنظمة القديمة) | تقنيات معالجة سياق البيانات الطويلة (ثورة 2026) |
|---|---|---|
| حجم البيانات المستوعبة في المرة الواحدة | مقال واحد منفرد أو بضعة أسطر مجزأة (4×103 رموز كحد أقصى) | مواقع ومدونات كاملة بملفات أدائها وتقاريرها (2×106 رموز) |
| آلية فهم الربط الداخلي | سطحي، يعتمد على الكلمات المفتاحية المتطابقة حرفياً وميكانيكياً | عميق، يعتمد على الروابط الدلالية والفهم الموضوعي الشامل للموقع ككل |
| مخرجات تحسين محركات البحث (SEO) | خطط كلمات مفتاحية مجزأة، روابط عشوائية، ومخاطر عالية للوقوع في المحتوى المكرر | خريطة محتوى متكاملة ومرجعية تخلو تماماً من “Low Value Content” |
| سرعة اتخاذ القرارات الإستراتيجية | أيام وأسابيع من التحليل البشري اليدوي لربط التقارير ببعضها | ثوانٍ معدودة لربط آلاف المتغيرات وإنتاج توصيات فورية قابلة للتطبيق |
6. خطوات عملية وممنهجة: كيف تبدأ وتطبق الآن؟
إذا كنت تسعى لتحويل مدونتك أو موقعك إلى مرجع تقني يتصدر نتائج عام 2026 باستخدام هذه التقنية، اتبع هذه الخطوات التنفيذية بدقة:
- الخطوة الأولى: تصدير وتجميع الكتلة البيانية: اذهب إلى لوحة تحكم موقعك وأدوات السيو (مثل Google Search Console) وقم بتحميل تقارير الأداء الكاملة، بالإضافة إلى نصوص مقالاتك المستهدفة بصيغة ملفات نصية مدمجة أو ملفات CSV معقدة.
- الخطوة الثانية: اختيار المنصة والنموذج الفائق: اعتمد على نماذج الذكاء الاصطناعي الحديثة التي توفر نوافذ سياق ضخمة (مثل النماذج الفائقة المدعومة من Google أو OpenAI لعام 2026 والتي تتسع لأكثر من مليون رمز).
- الخطوة الثالثة: صياغة أمر المعالجة السياقية العميقة: ارفع ملفاتك دفعة واحدة وصغ أمراً ذكياً يركز على معالجة الكتلة كاملة، مثل: “حلل بنية هذا الموقع المعرفية، واستخرج الروابط الموضوعية المفقودة بين الأقسام، وحدد بدقة أين تكمن مواطن الضعف التي تسببت في تصنيف بعض الصفحات كمحتوى قليل القيمة”.
- الخطوة الرابعة: التنفيذ والتحديث المعرفي الميداني: خذ مخرجات التحليل، وابدأ فوراً في دمج المقالات السطحية، وتحسين شبكة الروابط الداخلية. ولتطبيق هذا باحترافية، يُنصح بمراجعة أدلتنا التخصصية السابقة في مدونة البعد التقني الرابع حول إستراتيجيات السيو المتقدمة وهندسة الروابط لبناء بنية رقمية لا تقهر.
7. حدود التقنية وإشارات الثقة (ما لا يمكنها فعله)
امتثالاً للامانة العلمية والحيادية المطلقة التي تفرضها علينا قيمنا المهنية، يجب أن نوضح حدود هذه التقنية بوضوح؛ إن تقنيات معالجة سياق البيانات الطويلة —على الرغم من قدراتها التحليلية الفائقة والمهولة— هي مجرد أداة تحليلية ورسم خرائط بيانات. هذه التقنية لا يمكنها بأي حال من الأحوال أن تحل محل “اللمسة البشرية المبدعة” أو “التجربة الذاتية الحقيقية” التي يخوضها الكاتب المحترف بنفسه.
التقنية تكشف لك الأرقام، وتحدد الفجوات، وترسم لك مسار السيو الأمثل، ولكنها تعجز تماماً عن صياغة قصة نجاح إنسانية ملهمة، أو ابتكار أسلوب أدبي وثقافي مشوق يلمس مشاعر وعقول القراء ويجعلهم يثقون في علامتك التجارية. الذكاء الاصطناعي يمنحك الهيكل، وعقلك وخبرتك هما من يمنحان المقال روحه وقيمته المرجعية الفريدة.
8. خلاصة ذكية ورؤية مستقبلية
إن الانتقال نحو الاعتماد على تقنيات معالجة سياق البيانات الطويلة لم يعد مجرد خيار تقني ترفي أو رفاهية برمجية في عام 2026؛ بل هو خط الدفاع الأول والأداة الفاصلة الحاسمة بين المواقع التقليدية التي تنتج محتويات مجزأة ومكررة تلتهمها تحديثات الخوارزميات، والمواقع المرجعية العملاقة التي تبني بيئة معرفية متكاملة ومستدامة. الرؤية المستقبلية القريبة تؤكد بما لا يدع مجالاً للشك أن محركات البحث العالمية ستكافئ وتدفع نحو الصدارة فقط أولئك الذين يفهمون سياق مواقعهم بالكامل، ويقدمون للزائر تجربة مستخدم علمية، حقيقية، وخالية تماماً من الحشو الرقمي الزائد.
9. المصادر الرسمية المعتمدة (معايير E-E-A-T) والروابط المرجعية
- Google AI Research: الأوراق البحثية الرسمية من جوجل حول تطوير فهم السياق الممتد في خوارزميات الترتيب.
- OpenAI Technical Documentation: التوثيقات الفنية الرسمية المستعرضة للقدرات الاستيعابية الموسعة لنوافذ السياق (Long-Context).
- موقع البحث والتحليل المرجعي: لمتابعة المزيد من التحليلات العميقة، تفضل بزيارة مدونة البعد التقني الرابع.
10. قسم الأسئلة الشائعة وتثبيت المفاهيم (FAQ)
ج: نعم، التأثير ضخم جداً ولكنه يمر عبر قنوات غير مباشرة. عندما تنجح هذه التقنيات في بناء سياق موضوعي مترابط وخالٍ من التناقض والتكرار، وتصبح شبكة الروابط الداخلية منسوجة بمنطقية دلالية عالية، تجد عناكب محركات البحث (Googlebots) مسارات واضحة وسلسة للغاية أثناء الزحف، مما يمكنها من قراءة وفهم وأرشفة صفحات موقعك بالكامل في أوقات قياسية مقارنة بالمواقع العشوائية.
ج: على الإطلاق، لا تحتاج لكونك مبرمجاً لتستفيد من هذه الثورة. كل ما يتطلبه الأمر هو امتلاك مهارة تنظيم وتقييم بيانات موقعك، واستخراجها بصيغ ملفات نصية منظمة أو جداول بيانات بسيطة (CSV)، ومن ثم رفعها مباشرة إلى واجهات الأنظمة الذكية الفائقة المتاحة للمستخدمين، وصياغة أوامر (Prompts) تحليلية واضحة تعتمد على الفهم المنطقي وليس الأكواد البرمجية.
