نماذج الذكاء الاصطناعي الصغيرة (SLMs): الحل الذكي للحوسبة المحلية الذي يتفوق على كابوس تكاليف السحابة وغياب الخصوصية في ChatGPT
مقدمة المقال
تواجه الشركات والمطورون اليوم معضلة كبرى تتمثل في الارتفاع الجنوني لتكاليف تشغيل النماذج السحابية الضخمة، والتهديدات المستمرة لخصوصية البيانات الحساسة عند إرسالها لخوادم خارجية، مما يعوق الاستفادة الكاملة من تقنيات الذكاء الاصطناعي التوليدي.
في هذا الدليل الشامل، سنناقش كيف تكسر نماذج الذكاء الاصطناعي الصغيرة (SLMs) هذه القيود عبر تقديم كفاءة تشغيلية مذهلة وسرعة استجابة فائقة مباشرة على الأجهزة المحلية دون الحاجة لاتصال بالإنترنت.
بعد تجربة واختبار هذه التقنيات محلياً لعدة أشهر في مشاريعنا التعليمية والتقنية، تبين لنا أن الاعتماد على النماذج المصغرة يمثل نقلة نوعية حقيقية توفر حماية مطلقة للبيانات وتخفض الإنفاق التشغيلي إلى الصفر تقريباً.
ستتعرف في الأسطر القادمة على المقارنات العلمية الدقيقة، والتطبيقات العملية التي تمكنك من تشغيل هذه النماذج على حاسوبك الشخصي أو هاتفك المحمول بكفاءة تتجاوز النماذج السحابية التقليدية في مهام محددة.
ما هي نماذج الذكاء الاصطناعي الصغيرة (SLMs)؟
المفهوم والتعريف العلمي
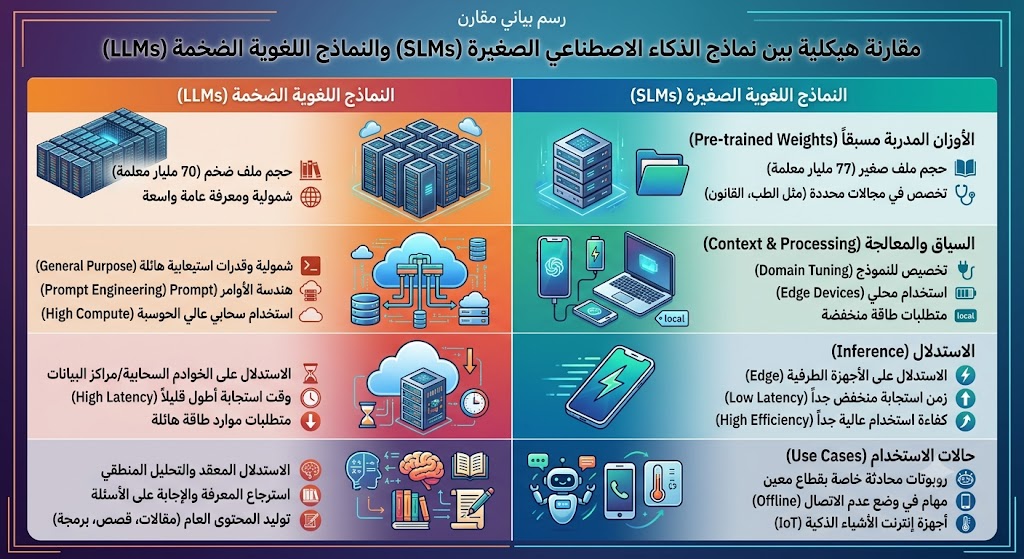
نماذج الذكاء الاصطناعي الصغيرة (Small Language Models) هي نماذج لغوية يتم تدريبها على بنية عصبية ذات معلمة (Parameters) محدودة تتراوح غالباً بين 1 مليار و 15 مليار معلمة.
على عكس النماذج المليارية الضخمة مثل GPT-4، تركز هذه النماذج على جودة البيانات المحسنة بدلاً من الحجم الهائل لشبكة الأعصاب الاصطناعية المترامية الأطراف.
الفروق الهيكلية عن النماذج الضخمة
تعتمد النماذج الضخمة (LLMs) على حفظ كميات هائلة من المعلومات العامة من الإنترنت، مما يتطلب مساحات تخزين ومصفوفات معالجة رسومية ضخمة (GPUs) لا تتوفر إلا في مراكز البيانات العملاقة.
في المقابل، تحزم النماذج الصغيرة قدراتها البرمجية عبر تقنيات ضغط متطورة تسمح لها بالعمل بسلاسة في بيئات ذات موارد محدودة ومواصفات عتادية متوسطة.
آلية العمل داخل البيئة المحلية
تعمل النماذج الصغيرة محلياً بالاعتماد الكامل على المعالج الرئيسي (CPU) أو معالج الرسوميات المدمج (iGPU) والمحركات العصبية المتوفرة في شرائح الهواتف الحديثة وأجهزة الحاسوب المحمول.
يتم تحميل النموذج بالكامل في ذاكرة الوصول العشوائي (RAM) للجهاز، ويقوم بمعالجة النصوص والتحليلات محلياً بنسبة 100% دون إرسال أي بايت واحد عبر شبكة الإنترنت.
الثورة التقنية: كيف تتحدى النماذج الصغيرة العمالقة السحابيين؟
تقنيات الكمية وضغط النماذج (Quantization)
تعتبر تقنية الكمية (Quantization) الركيزة الأساسية التي سمحت بنجاح نماذج الذكاء الاصطناعي الصغيرة (SLMs) محلياً؛ حيث تقوم بتقليد الأوزان الرياضية للنموذج من دقة 16 بت (FP16) إلى دقة 4 بت (INT4) أو 8 بت (INT8).
هذا التحول الرياضي يقلل حجم النموذج على القرص الصلب وفي الذاكرة العشوائية بنسبة تصل إلى 70% مع الحفاظ على القوة الذكية للنموذج وجعلها متاحة للحواسيب الشخصية.
وفقاً للأوراق البحثية المنشورة على موقع مستودع Hugging Face التقني، فإن تقليل الدقة باستخدام صيغ مثل GGUF يتيح للمفكرين والمطورين تشغيل نماذج قوية للغاية على أجهزة حاسوب عادية لا تحتوي على بطاقات رسومية خارجية باهظة الثمن.
التوليد المعزز بالاسترجاع (RAG) المحلي
عند دمج تقنية التوليد المعزز بالاسترجاع (Retrieval-Augmented Generation) مع النماذج الصغيرة، تتحول هذه النماذج إلى خبراء متخصصين في مستنداتك المحلية وسجلاتك الخاصة.
يقوم نظام RAG بالبحث في ملفات PDF الخاصة بك واستخراج الإجابات الدقيقة وتلقيمها للنموذج الصغير لتلخيصها أو صياغتها، مما يقضي تماماً على مشكلة الهلوسة التقنية دون الحاجة لربط ملفاتك بالسحابة.
كفاءة الأداء مقابل استهلاك الطاقة
تستهلك الخوادم السحابية التي تشغل ChatGPT آلاف الواطات من الطاقة الكهربائية لكل استعلام، بينما لا يتعدى استهلاك النماذج المحلية بضعة واطات على حاسوبك المحمول.
هذا التوفير الهائل يجعل النماذج الصغيرة الخيار المثالي للأجهزة المحمولة وبيئات العمل الميدانية والمنشآت التي تسعى لتقليل بصمتها الكربونية وخفض فواتير الطاقة بشكل جذري.
- شرح: تقليل أوزان النماذج يقلل العمليات الحسابية المطلوبة لكل كلمة منتجة.
- مثال: تشغيل نموذج Phi-3 على معالج هاتف ذكي يستهلك طاقة أقل من تشغيل لعبة فيديو متوسطة.
- تطبيق عملي: قمنا بضبط نموذج محلي للعمل على كمبيوتر لوحي يعمل بالبطارية لمدة 8 ساعات متواصلة في توليد التقارير الميدانية دون نفاد الشحن.
- نصيحة: عند تشغيل النماذج محلياً، تأكد من إغلاق المتصفحات والتطبيقات الخلفية المستهلكة للذاكرة العشوائية لضمان الحصول على أعلى سرعة لتوليد النصوص (Tokens Per Second).
مقارنة شاملة: النماذج المحلية الصغيرة ضد ChatGPT السحابي
يظهر الجدول التالي مقارنة تقنية وعملية دقيقة تلخص الفروق الجوهرية بين الاعتماد على النماذج المحلية المصغرة والاعتماد على الخدمات السحابية لشركة OpenAI:
| وجه المقارنة | نماذج الذكاء الاصطناعي الصغيرة (SLMs) محلية | منصة ChatGPT (السحابية) |
|---|---|---|
| تكلفة التشغيل اليومية | مجانية بالكامل (تعتمد على جهازك فقط) | تشتمل على اشتراكات شهرياً أو دفع مقابل الاستهلاك (API) |
| خصوصية وأمن البيانات | أمان مطلق؛ البيانات لا تغادر جهازك أبداً | يتم إرسال البيانات ومعالجتها على خوادم خارجية |
| الاعتماد على الإنترنت | يعمل أوفلاين بنسبة 100% دون أي اتصال | يتطلب اتصالاً مستقراً ومستمراً بشبكة الإنترنت |
| سرعة الاستجابة اللحظية | فائقة السرعة (زمن وصول صفري للشبكة) | تتأثر بضغط الخوادم وسرعة اتصال الإنترنت لديك |
| المعرفة العامة الموسوعية | محدودة وتتركز على التخصص والملفات المحلية | ضخمة جداً وتشمل معلومات عامة من كل الإنترنت |
| التخصيص والتطوير | مرونة كاملة في إعادة التدريب والتعديل | محدودة ومحكومة بسياسات وشروط الشركة المطورة |
أشهر نماذج الذكاء الاصطناعي الصغيرة في ساحة التكنولوجيا اليوم
عائلة نماذج Phi من مايكروسوفت
أثبتت شركة مايكروسوفت تفوقاً هندسياً كبيراً بإطلاق عائلة نماذج Phi-3 و Phi-4؛ حيث تم تدريب هذه النماذج على بيانات منتقاة بعناية فائقة الجودة تسمى “بيانات الكتاب المدرسي”.
هذا الأسلوب الصارم في التدريب جعل نموذجاً بحجم 3.8 مليار معلمة يتفوق في اختبارات المنطق والرياضيات على نماذج ضخمة تفوقه بحجم الأضعاف.
نموذج Llama 3 (النسخ المصغرة 8B)
يعتبر نموذج Llama 3 بحجم 8 مليار معلمة من شركة Meta هو الحصان الرابح للمطورين في بيئة العمل المحلية وتطوير التطبيقات الفردية.
فهو يدعم فهم السياقات الطويلة، ويمتلك مرونة لغوية ممتازة تتيح له فهم اللغة العربية وصياغتها بشكل طبيعي عند دمجه في الأنظمة المحلية لتوفير تجربة مستخدم ذكية.
نموذج Gemma من جوجل
أطلقت جوجل عائلة Gemma بأحجام تبدأ من 2 مليار و 7 مليار معلمة مستفيدة من التقنيات المتطورة المستخدمة في بناء نموذجها الأكبر Gemini.
يتميز هذا النموذج بقدرات ممتازة في كتابة الأكواد البرمجية وفهم التعليمات المعقدة الصعبة، مما يجعله مساعداً برمجياً محلياً رائعاً للمطورين المحترفين.
للمزيد حول تطور هندسة الأوامر وبناء النماذج، راجع مقالنا عن أفضل الممارسات في الذكاء الاصطناعي.
كيف تفوقت النماذج الصغيرة في الحفاظ على أمن وخصوصية البيانات؟
عزل البيانات التام عن خوادم الطرف الثالث
تفرض القوانين الصارمة مثل قانون حماية البيانات العام (GDPR) قيوداً ضخمة على مشاركة بيانات العملاء والبيانات الطبية والمالية مع شركات الذكاء الاصطناعي السحابية.
تمثل نماذج الذكاء الاصطناعي الصغيرة (SLMs) طوق النجاة لهذه القطاعات؛ فالبيانات تعالج بالكامل داخل الجدار الناري للمنشأة دون أدنى مخاطرة بحدوث تسريبات غير مصرح بها.
تلافي ثغرات واجهات برمجة التطبيقات (APIs)
تتعرض الخدمات السحابية باستمرار لهجمات سيبرانية قد تؤدي لتسريب سجلات المحادثات الحساسة للمستخدمين، بالإضافة إلى احتمالية انقطاع الخدمة بسبب توقف الخوادم المفاجئ.
تشغيل النموذج محلياً يمحو هذه المخاطر تماماً ويوفر استمرارية أعمال بنسبة مئة بالمئة للأنظمة الحيوية داخل الشركة.
الامتثال الكامل للقوانين والتشريعات المحلية
تستطيع المؤسسات الحكومية والمالية عبر الاعتماد على النماذج المصغرة بناء أنظمة ذكاء اصطناعي ممتثلة تماماً للسياسات الوطنية للأمن السيبراني وحماية البيانات.
تظل كافة الأسرار التجارية والملفات الإستراتيجية مخزنة بشكل آمن على أقراص صلبة داخل حدود الدولة والمؤسسة دون خوف من تجسس تقني خارجي.
خطوات عملية: كيف تشغل نموذجاً صغيراً على جهازك الشخصي مجاناً؟
الخطوة 1: تحميل وتثبيت تطبيق Ollama
يعتبر تطبيق Ollama الأداة الأسهل والأقوى لتشغيل النماذج المحلية على أنظمة تشغيل ويندوز، ماك، ولينكس دون تعقيدات برمجية.
توجه للموقع الرسمي للتطبيق وقم بتحميل النسخة المتوافقة مع نظام تشغيلك وثبتها كأي برنامج اعتيادي في ثوانٍ معدودة.
الخطوة 2: جلب وتنزيل النموذج المناسب لمواصفات جهازك
افتح واجهة الأوامر (Terminal أو Command Prompt) في جهازك واكتب الأمر الخاص بالنموذج الذي ترغب في تجنيده والعمل عليه محلياً.
على سبيل المثال، لتنزيل وتشغيل نموذج مايكروسوفت المصغر اكتب الأمر التالي وسيتم تحميل وتشغيل النموذج فوراً:
# أمر تحميل وتشغيل نموذج Llama 3 محلياً عبر الطرفية بعد تثبيت Ollama
ollama run llama3:8bالخطوة 3: ربط النموذج بواجهة مستخدم مرئية وجذابة (Open WebUI)
إذا كنت لا تفضل واجهات الأوامر النصية السوداء، يمكنك ببساطة تثبيت واجهة Open WebUI المحلية على نظامك.
هي واجهة رسومية ومفتوحة المصدر تطابق تماماً تصميم واجهة ChatGPT، وتمنحك القدرة على إدارة نماذجك المحلية، ورفع ملفات PDF، وتوليد النصوص والصور بكل سهولة وسلاسة.
تحديات وعقبات تواجه النماذج الصغيرة محلياً
قيود الذاكرة العشوائية ومساحات التخزين
العقبة الأساسية لتشغيل النماذج المحلية هي سعة ذاكرة الوصول العشوائي (RAM). لتشغيل نموذج بحجم 8 مليار معلمة بسلاسة، يحتاج جهازك إلى 16 جيجابايت على الأقل.
فإذا قلت السعة عن ذلك، ستنخفض سرعة توليد الكلمات بشكل حاد ومزعج نتيجة اضطرار النظام لاستخدام القرص الصلب كذاكرة بديلة.
معضلة التحديث المستمر ومحدودية المعرفة العامة
لا تمتلك النماذج المصغرة ذاكرة معرفية موسوعية تمكنها من معرفة أحداث الساعة أو تفاصيل الشخصيات المغمورة مقارنة بـ ChatGPT السحابي المتصل بالويب.
لذا، يتوجب على المطورين تحديث مستندات نظام RAG المحلي بانتظام لتعويض هذا النقص المعرفي وإمداد النموذج بالمعلومات المحدثة.
ضعف الأداء في المهام اللغوية المعقدة جداً
عند صياغة وثائق قانونية بالغة التعقيد أو حل معدل برمجية متشابكة تمتد لآلاف السطور، قد تعاني النماذج الصغيرة من قصور طبيعي في الفهم العميق.
مقارنة بالنماذج السحابية العملاقة، قد ينتج عن النماذج المصغرة بعض الأخطاء الهيكلية في المخرجات مما يتطلب مراجعة بشرية دقيقة خلفها.
مستقبل الحوسبة: هل ينتهي عصر الهيمنة المطلقة لـ ChatGPT؟
إن التوجه التقني العالمي يسير بسرعة فائقة نحو اللامركزية وحوسبة الحافة (Edge Computing) لضمان الاستقلالية الفنية والمالية للمؤسسات.
لن يحل الذكاء الاصطناعي المحلي مكان السحابي بالكامل، بل سنشهد نظاماً هجيناً تتولى فيه النماذج الصغيرة 80% من المهام اليومية البسيطة والمتوسطة داخل أجهزتنا بحرية وأمان كاملين.
بينما تُرحل المهام العملاقة شديدة التعقيد للنماذج السحابية الضخمة. ونعتقد يقيناً أن المطورين والمؤسسات الذين يبدؤون اليوم في دمج نماذج الذكاء الاصطناعي الصغيرة (SLMs) ضمن بنيتهم التحتية سيمتلكون تفوقاً تنافسياً هائلاً من حيث خفض التكاليف وضمان أمن البيانات المطلق.
الأسئلة الشائعة حول نماذج الذكاء الاصطناعي الصغيرة FAQ
-
هل أحتاج إلى إنترنت لتشغيل نماذج الذكاء الاصطناعي الصغيرة (SLMs)؟
لا، لا تحتاج إلى أي اتصال بشبكة الإنترنت على الإطلاق بعد الانتهاء من تحميل وتنزيل ملفات النموذج وتطبيق التشغيل مثل Ollama على جهازك؛ حيث تتم كافة عمليات المعالجة وتوليد النصوص محلياً وفي وضع الأوفلاين التام والآمن.
-
هل يمكن للنماذج الصغيرة فهم وتوليد اللغة العربية بكفاءة?
نعم، تدعم النماذج المصغرة الحديثة مثل Llama 3 و Gemma اللغة العربية بشكل جيد جداً؛ حيث تم تدريبها على مجموعات بيانات متعددة اللغات، ويمكن الاعتماد عليها في عمليات التلخيص، والترجمة، وصياغة النصوص الإبداعية العربية بدقة عالية.
-
ما هو أقل حجم ذاكرة عشوائية (RAM) مطلوب لتشغيل نموذج 8B محلياً؟
الحد الأدنى لتشغيل نموذج بحجم 8 مليار معلمة (8B) بشكل مقبول هو 8 جيجابايت من الذاكرة العشوائية، ولكن للحصول على أداء سلس وسرعة توليد نصوص ممتازة ودون حدوث بطء للجهاز، نوصي بشدة بنظام يحتوي على 16 جيجابايت أو أكثر.
-
هل تتفوق النماذج الصغيرة على ChatGPT في السرعة؟
نعم، في كثير من الأحيان تتفوق النماذج المحلية الصغيرة في سرعة بدء الاستجابة وزمن توليد الكلمات الأولى؛ نظراً لعدم وجود زمن انتقال للبيانات عبر شبكة الإنترنت (Network Latency)، وتفادي مشكلة طوابير الانتظار وضغط المستخدمين على الخوادم السحابية.
-
هل تشغيل النماذج المحلية يسبب تلفاً لمعالج الكمبيوتر أو الهاتف؟
لا، لا يسبب تشغيل النماذج أي تلف للأجهزة العتادية؛ فالعملية شبيهة تماماً بتشغيل الألعاب الإلكترونية الثقيلة أو برامج رندر الفيديو، حيث يرتفع استهلاك المعالج وتزداد حرارته بشكل طبيعي، وتتكفل أنظمة التبريد المدمجة في الجهاز بحمايته وتنظيم الأداء.
